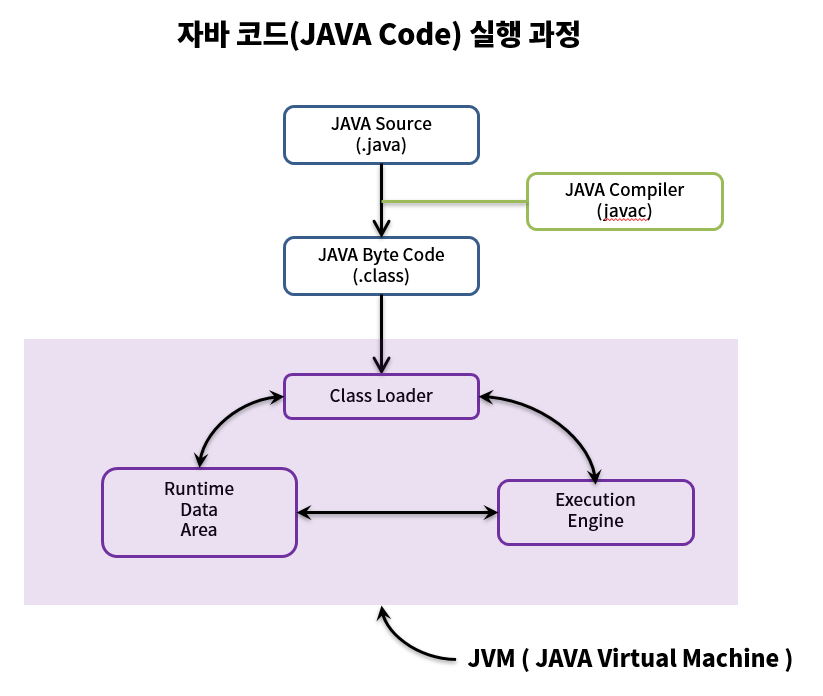
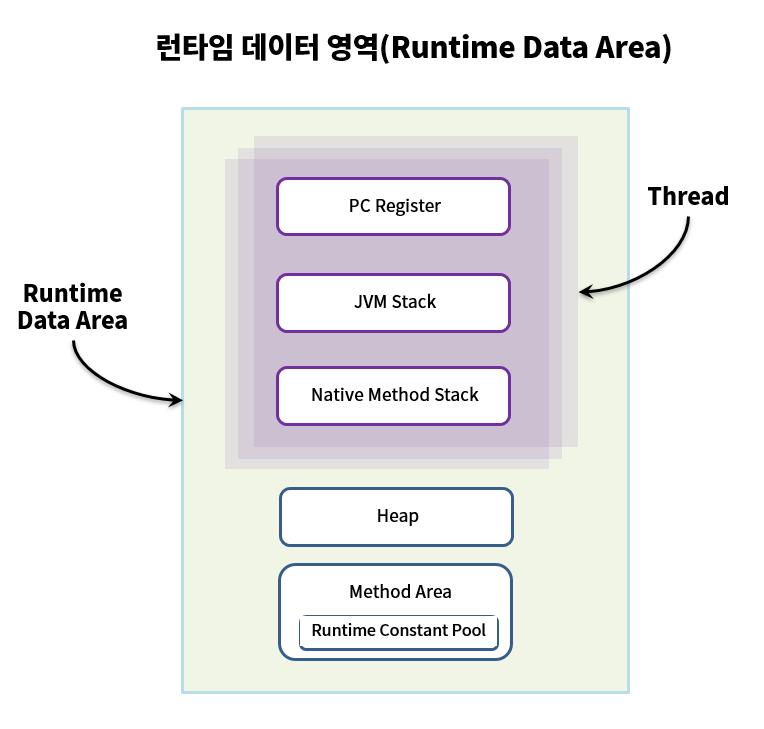
Serialization(직렬화)
- 자바 시스템 내부에서 사용되는 객체 또는 데이터를 외부의 자바 시스템에서도 사용할 수 있도록 바이트 형태로 데이터를 변환하는 기술
- 각자 PC의 OS마다 서로 다른 가상 메모리 주소 공간을 갖기 때문에, Reference Type의 데이터들은 인스턴스를 전달 할 수 없다.
- 따라서, 이런 문제를 해결하기 위해선 주소값이 아닌 Byte형태로 직렬화된 객체 데이터를 전달해야 한다.
- 직렬화된 데이터들은 모두 기본형이 되고, 이는 파일 저장이나 네트워크 전송 시 파싱이 가능한 유의미한 데이터가 된다. 따라서 전송 및 저장이 가능한 데이터로 만들어 주는 것이 바로 직렬화이다.
직렬화 조건
- 자바에서는 간단히 java.io.Serializable 인터페이스 구현으로 직렬화/역직렬화가 가능하다.
- 직렬화 대상
- 인터페이스 상속 받은 객체,
- Primitive 타입의 데이터
- Primitive 타입이 아닌 Reference 타입처럼 주소값을 지닌 객체들은 바이트로 변환하기 위해 Serializable 인터페이스를 구현해야 한다.
직렬화 방법
- java.io.ObjectOutputStream 객체를 이용한다.
Member member = new Member("홍길동", "hong@hong.com", 25);
byte[] serializedMember;
try (ByteArrayOutputStream baos = new ByteArrayOutputStream()) {
try (ObjectOutputStream oos = new ObjectOutputStream(baos)) {
oos.writeObject(member);
// serializedMember -> 직렬화된 member 객체
serializedMember = baos.toByteArray();
}
}
// 바이트 배열로 생성된 직렬화 데이터를 base64로 변환
System.out.println(Base64.getEncoder().encodeToString(serializedMember));
}
역직렬화 조건
- 직렬화 대상이 된 객체의 클래스가 클래스 패스에 존재해야 하며 import 되어 있어야 한다.
- 중요한 점은 직렬화와 역직렬화를 진행하는 시스템이 서로 다를 수 있다는 것을 반드시 고려해야 한다.
💡 자바 직렬화 대상 객체는 동일한 serialVersionUID를 가지고 있어야 한다(필수는 아님)
자바의 직렬화 왜 사용될까?
- CSV, JSON 프로토콜 버퍼 등은 시스템의 고유 특성과 상관없는 대부분의 시스템에서의 데이터 교환 시 많이 사용된다. 하지만 자바 직렬화 형태의 데이터 교환은 자바 시스템 간의 데이터 교환을 위해서 존재한다.
그렇다면 자바에서도 CSV, JSON을 사용하면 되지 자바 직렬화를 써야 되는 이유가 있을까?
- 정답은 없지만 목적에 따라 적절하게 써야한다.
- 직렬화의 장점
- 자바 시스템에서 개발에 최적화 되어 있다.
- 복잡한 데이터 구조의 클래스의 객체라도 직렬화 기본 조건만 지키면 큰 작업 없이 바로 직렬화가 가능하다.
- 데이터 타입이 자동으로 맞춰진다.
- 직렬화의 단점
- 변경에 취약하기 때문에 예외사항이 발생할 가능성이 높다.
- 다른 포맷에 비해서 용량이 크다.
자바 직렬화는 언제 어디서 사용될까?
- 서블릿 세션
- 서블릿 기반의 WAS들은 대부분 세션의 자바 직렬화를 지원하고 있다. 물론 단순히 세션을 서블릿 메모리 위에서 운용한다면 직렬화를 필요로 하지 않지만 파일로 저장하거나 세션 클러스터링, DB를 저장하는 옵션 등을 선택하게 되면 세션 자체가 직렬화 되어 저장되어 전달된다.
- 캐시
- 자바 시스템에서 퍼포먼스를 위해 캐시 라이브러리 시스템을 많이 이용하게 된다. 개발을 하다보면 상당수의 클래스가 만들어지게 된다 예를들어 DB를 조회한 후 가져온 데이터 객체 같은 경우 실시간 형태로 요구하는 데이터가 아니라면 메모리, 외부 저장소, 파일 등을 저장소를 이용해서 데이터 객체를 저장한 후 동일한 요청이 오면 DB를 다시 요청하는 것이 아니라 저장된 객체를 찾아서 응답하게 하는 형태를 보통 캐시를 사용한다고 한다.
- 이렇게 캐시할 부분을 직렬화하여 저장해서 사용한다. 자바 직렬화만을 이용해서 캐시를 저장하지는 않지만 가장 간편하기 때문에 많이 사용된다.
'Computer science > JAVA' 카테고리의 다른 글
| Object Class (0) | 2023.01.01 |
|---|---|
| String Class (0) | 2023.01.01 |
| 오토 박싱 & 오토 언박싱 (0) | 2022.12.25 |
| Primitive type & Reference type (0) | 2022.12.24 |
| Call by value와 Call by reference (0) | 2022.12.24 |